
Pro SQL Sever Internals - Ch#2 - Tables and Indexes
Internal Structure and Access Methods


Sql server stores data in tables and indexes. They represent a collection of data pages with rows that belong to a single entity or object.
In this chapter, we will talk about the internal structure of index =, cover how sql server uses them, and discuss how to write queries in a way that efficiently utilize them.
Heap Tables
Heap tables are tables w/o a clustered index. The data in heap tables is unsorted.Sql doesn't gurantee, nor does it maintain, a sorting of the data in heap tables.
When inserting data into heap tables, sql tries to fill pages as mush as possible, although it doesn't analysis the actual free space available on a page. it uses the page free space ( PFS ) allocation map instead.
If a data page store 4100 bytes of data, and as result it has 3960 bytes of free space available, PFS would indicate that the page is 51-80% full. Sql would not put a new row on the page if its size exceeds 20% (8060 bytes * 0.2 = 1612 bytes) of page size.
-- create heap table
create table dbo.Heap
(
Val varchar(8000) not null
);
-- insert data into heap table
;with CTE(ID,Val)
as
(
select 1, replicate('0',4089)
union all
select ID + 1, Val from CTE where ID < 20 )
insert into dbo.Heap
select Val from CTE;
select
page_count,
avg_record_size_in_bytes,
avg_page_space_used_in_percent
from
sys.dm_db_index_physical_stats(
db_id(),
object_id(N'dbo.Heap'),
0,
null,'DETAILED');

At this point, the table stores 20 rows of 4100 bytes each. sql allocates 20 data pages - 1 page/row - w/ 3960 bytes available. PFS would indicate that pages are 51-80% full.
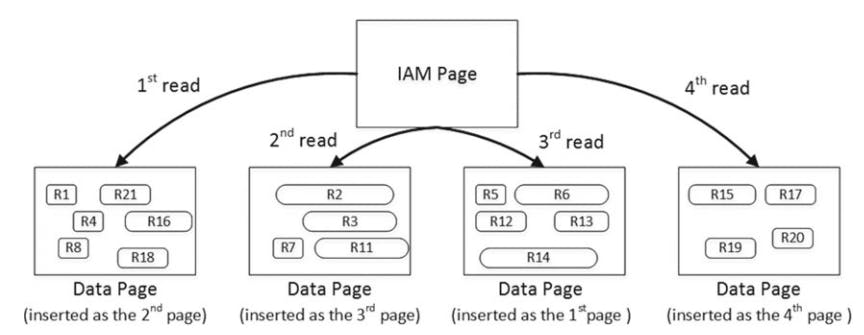
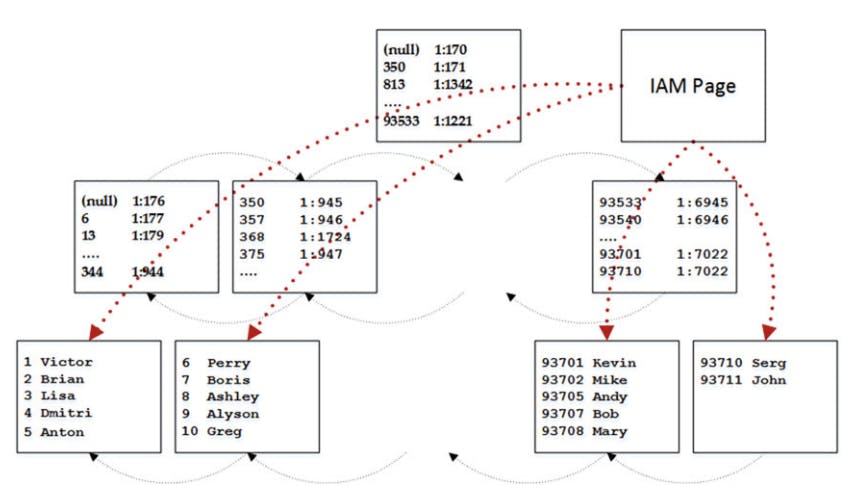
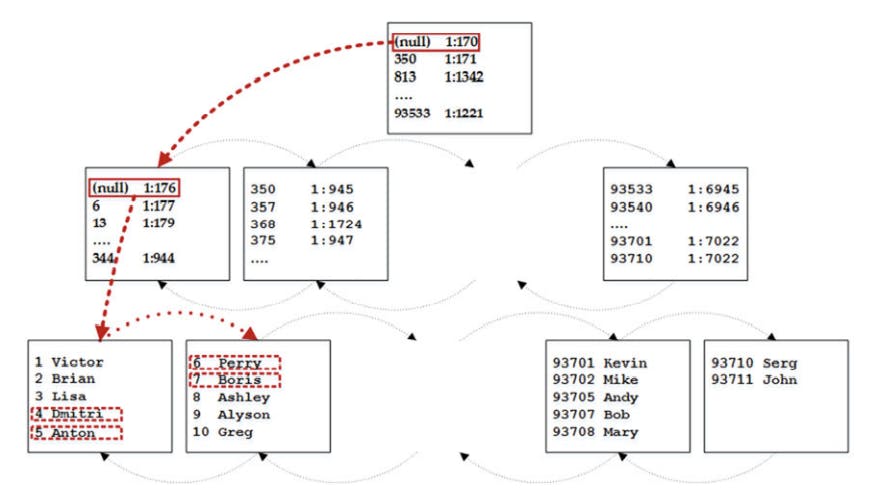
when Selecting data from the heap table, sql uses an index allocation map ( IAM ) to find the pages and extends that need to be scanned. It analyses what extends belongs to the table and processes them based on their allocation order rather than on the order in which the data was inserted.
image shows the selecting data from heap table
when you update a row in the heap table, sql tries to accommodate it on the same page. If there is no free space available, sql moves the new version of the row to aonthor page and replace the old row w/ a special 16-byte row called a forwarding pointer. The new version of the row is called forwarded row
Forwarding pointers
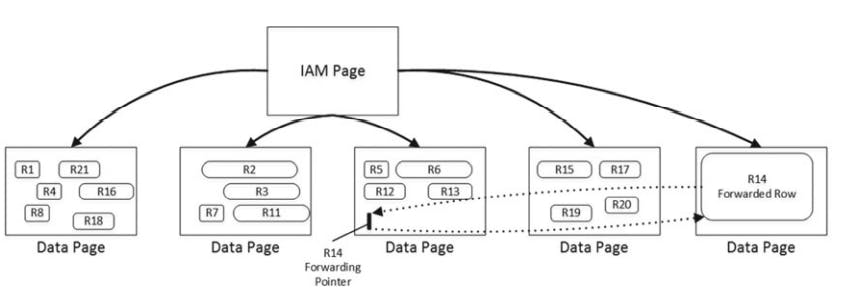
There are two main reasons why forwarding pointers are used.
- first: they prevents updates of nonclustered index keys that reference the row.
- second: forwarding pointers help minimize the number of duplicated reads, that is, situation in which a single row is read multiple times during a table scan.
With forwarding pointers, sql would ignore the forwarded rows- they have a bit set in the status Bits A byte in the data row.
Forwarding pointers and IO: table creation and three row inserted.
create table dbo.ForwardingPointers
(
ID int not null,
Val varchar(8000) null
);
insert into dbo.ForwardingPointers(ID,Val)
values(1,null),(2,replicate('2',7800)),(3,null);
select page_count, avg_record_size_in_bytes, avg_page_space_used_in_percent
,forwarded_record_count
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.ForwardingPointers'),0
,null,'DETAILED');
set statistics io on
select count(*) from dbo.ForwardingPointers;
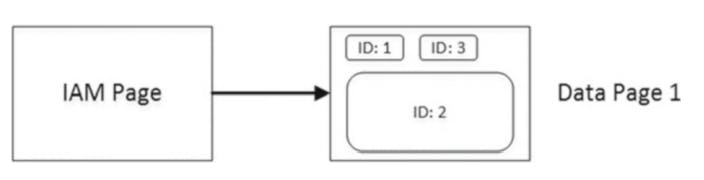
The following is the output of code

As you can see in next image, all 3 rows fit into the single page, and sql needs to read just that page when it scans the table.
Forwarding pointers and I/O: Data pages after table creation.
when updating 2 of table rows by increasing their size. The new versions pf the rows will not fit into the page anymore, which introduces the allocation of 2 new pages and 2 forwarding pointers.
update dbo.ForwardingPointers set Val = replicate('1',5000) where ID = 1;
update dbo.ForwardingPointers set Val = replicate('3',5000) where ID = 3;
select page_count, avg_record_size_in_bytes, avg_page_space_used_in_percent, forwarded_record_count
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.ForwardingPointers'),0,null
,'DETAILED');
set statistics io on
select count(*) from dbo.ForwardingPointers
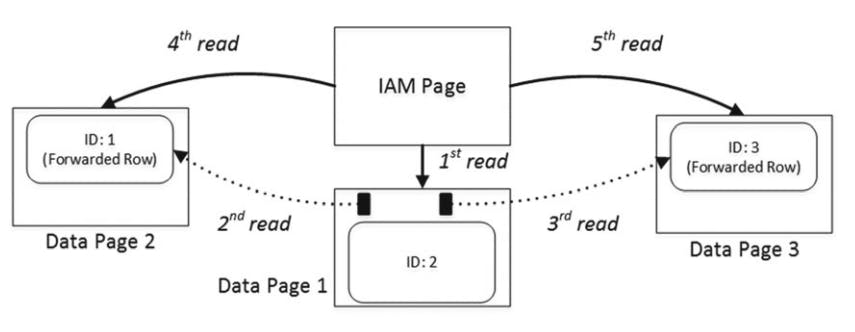
the following is the output of the code from listing

when sql reads the forwarding pointer row from page 1, it follows them and reads pages 2 and 3 immediately. After that, sql server reads those pages one more time during the regular IAM scan process.
forwarding pointers and I/O: reading data when forwarding pointer exists.
The large number of forwarding pointers leads to extra I/O operations and significantly reduces the performance of the queries accessing the data.
The only reliable way to get rid of all the forwarding pointers is by rebuilding the heap table. you can do that by using an Alter table rebuild statement.
Heap tables can be useful in staging environment where you wanna import a large amount of data into the system as fast as possible. Inserting data into heap tables can often be faster than inserting it into tables with clustered indexs
Clustered Indexes
A clustered index dictates the physical order of the data in a table, which is sorted according to the clustered index key. The table can have only one clustered index defined.
creating a clustered index on the heap table w/ the data. As a first step, which is shown in next figure, sql creates another copy of the data that is then sorted based on the value of the clustered key. The data pages are linked in a double-linked list where every page contains pointers to the next and previous pages in the chain. The list is called the leaf level of index and it contains the actual table data.
clustered index structure Leaf level
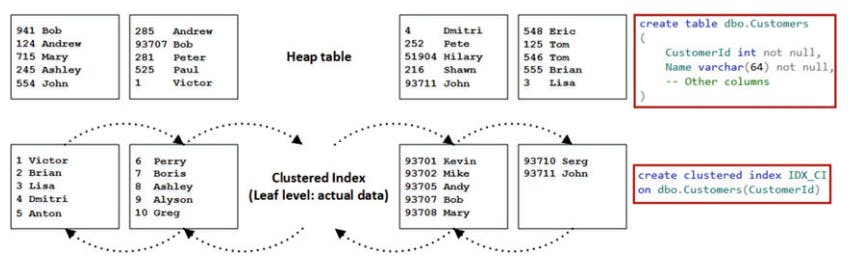
The sort order on the page is controlled by a slot array. Actual data on the page is unsorted
when the leaf level consists of multiple pages, sql starts to build an intermediate level of the index.
clustered index structure: Intermediate and leaf levels
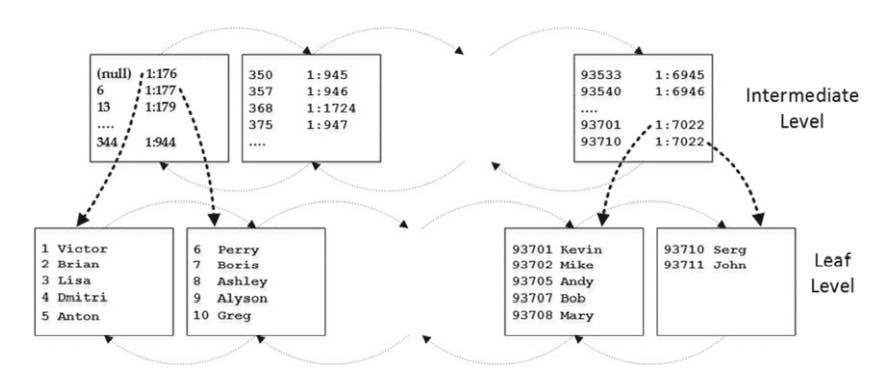
The intermediate level stores one row per leaf level page. It stores 2 pieces of information:
- the physical address.
- minimum value of the index key from the page it reference.
The pages on the intermediate levels are also linked to the double-linked list. Sql adds more intermediate level until there is a level that includes just single page root level
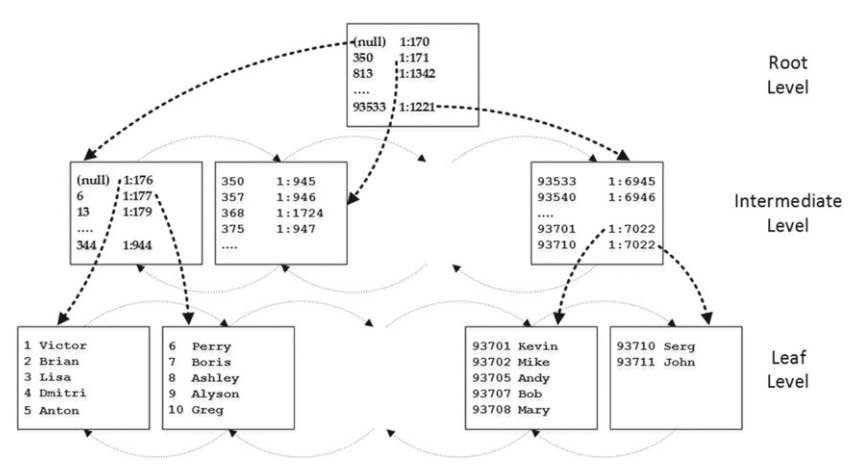 As you can see, the index always has one leaf level, one root level, and zero or more intermediate levels. The only exception is when the index data fits into a single page.
As you can see, the index always has one leaf level, one root level, and zero or more intermediate levels. The only exception is when the index data fits into a single page.
There are 3 different ways in which sql can read data from the index:-
- Order Scan, let's assume that we want to run the
SELECT Name FROM dbo.Customers ORDER BY CustomerId
The mechanism of order scan index.
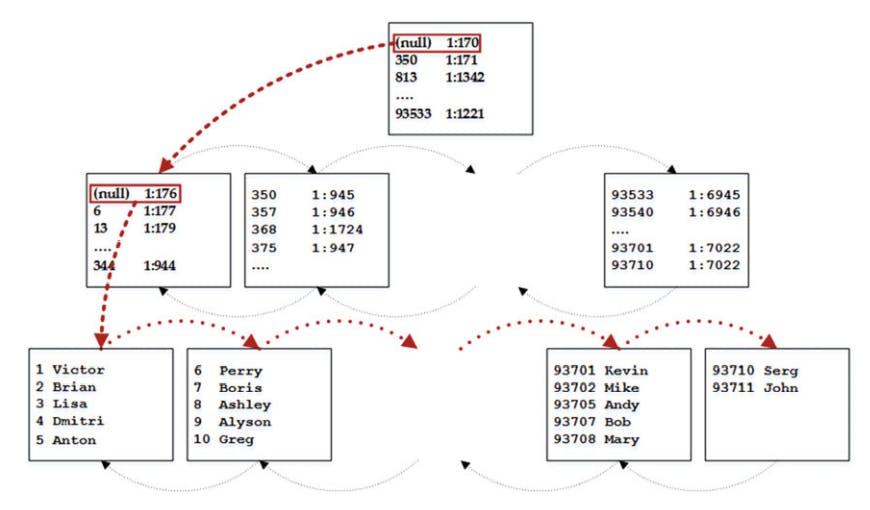
the execution plan for the preceding query shows the clustered index scan operator with ordered property set to true, as shown

It's worth mentioning that the order by clause is not required for an order scan to be triggered. An Order scan just means that SQL reads the data based on the order of the index key.
SQL server doesn't use parallelism during backward index scan

The Enterprise edition Sql Server has an Optimization feature called merry-go-round scan that allows multiple tasks to share the same index scan. let's assume that you have a session S1, which is scanning the index. At some point in the middle of the scan, another session S2, runs a query that needs to scan the only once, passing rows to both sessions.
When the S1 scans reaches the end of index, S2 starts scanning data from the begining of index until the point where the S2 scan start. A merry-go-round scan is another example of why you can't rely on the order of the index keys and why you should always specify an Order by clause when it matters.
The next access method after the order scan is called allocation order scan, Sql accesses the table data through the IAM pages, similar to how ot does so w/ heap tables.
SELECT Name FROM dbo.Customers WITH (NOLOCK)
next figure illustrates this method.
The execution plan of the above query
Allocation order scan execution plan.
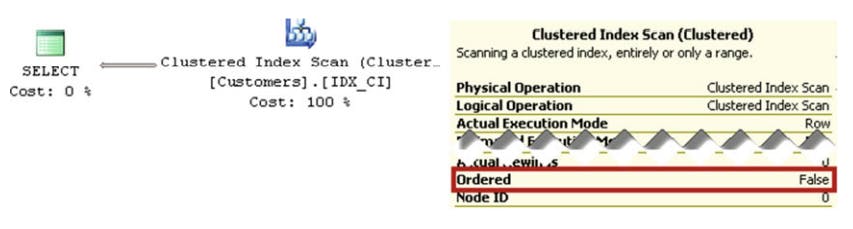
An Allocation order scan can be fast for scanning large tables, although it has a higher startup cost. sql doesn't use this access method when the table is small. Another important consideration is data consistency. sql server doesn't use forwarding pointers in tables that have a clustered index, and an allocation order scan can produce inconsistent results. Rows can be skiped or read multiple times due to the data movement caused by pages splits. As a result, Sql server usually avoids using allocation order scans unless it reads the data in READ UNCOMMITTED or SERIALIZABLE transaction isolation levels
select Name from dbo.Customers where CustomerId between 4 and 7
the execution plan of the above query
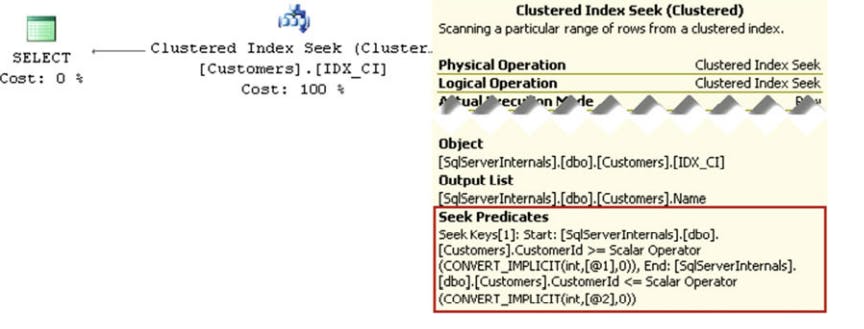
index seek is more efficient than the index scan, because sql server processes just the subset of rows and data pages rather than scanning the entire table.
There are 2 kind of index seek operations:-
- singleton lookup (point speaking), where sql server seeks and returns a single row.
- range scan, it requires sql to find the lowest or highest value of the key and scan, the set of rows until it reaches the end of scan range.
The predicate where CustomerId between 4 and 7 leads to the range scan. Both cases are shown as index seek operations in the execution plan.
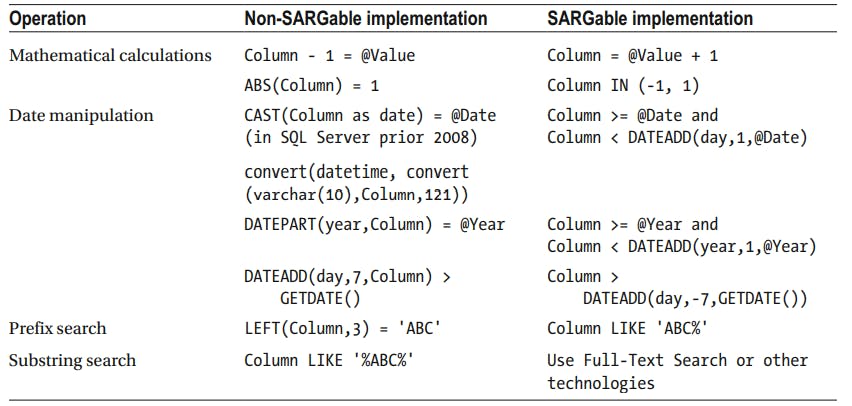
There is a concept in relational database called SARGable predicates, which stands for search Argument able. predicates are SARGable when sql can isolate the single value or range of index key values to process, thus limiting the search during predicate evaluation.
SARGable predicates includes following operators: =, <, >, <=, >=, IN, BETWEEN and LIKE(in case of prefix matching). Non SARGable operators includes NOT, <>, Like(in case of non prefix matching), using function or mathematical calculations against table columns
create table dbo.Data
(
VarcharKey varchar(10) not null,
Placeholder char(200)
);
create unique clustered index IDX_Data_VarcharKey
on dbo.Data(VarcharKey);
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows
,N5(C) as (select 0 from N4 as T1 cross join N4 as T2) -- 65,536 rows
,IDs(ID) as (select row_number() over (order by (select null)) from N5)
insert into dbo.Data(VarcharKey)
select convert(varchar(10),ID) from IDs;
the clustered index key column is defined as varchar, even though it stores integer values.
declare @IntParam int = '200'
select * from dbo.Data where VarcharKey = @IntParam;
select * from dbo.Data where VarcharKey = convert(varchar(10),@IntParam);
in case of the integer paramter, sql scans the clustered index, converting varchar to an integer for every row. In the second, sql converts the integer parameter to a varchar at the begining and utilizes a much more effient clustered index seek operation.
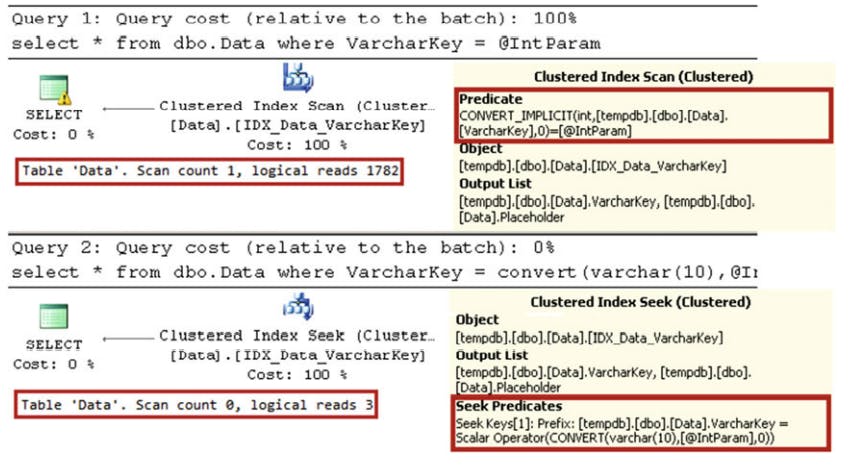
SARGable predicates and data types: select w/ string parameter
select * from dbo.Data where VarcharKey = '200';
select * from dbo.Data where VarcharKey = N'200'; -- unicode
-- parameter
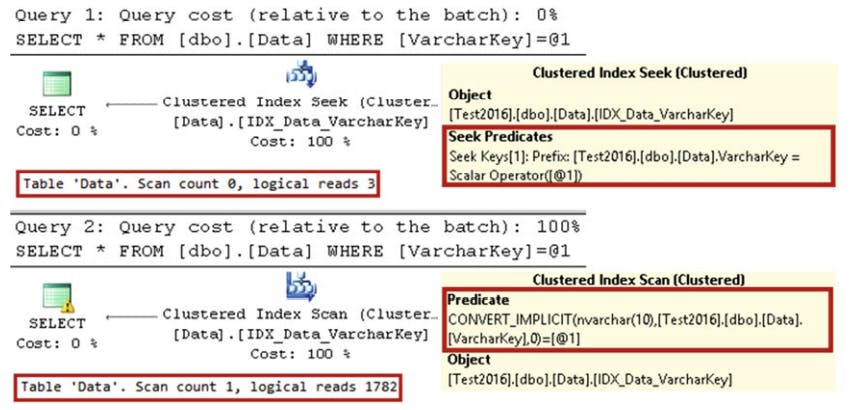
a unicode string parameter is non-SARGable for varchar columns. This is a much bigger issue than it appears to be.

it's also worth mentioning that varchar parameters are SARGable for nvarchar unicode data columns
Composite Indexes
index w/ multiple key columns are called composite ( compound) indexes. The data in the composite indexes is sorted on a per-column basis from leftmost to rightmost columns.
the next figure show the structure of a composite index.
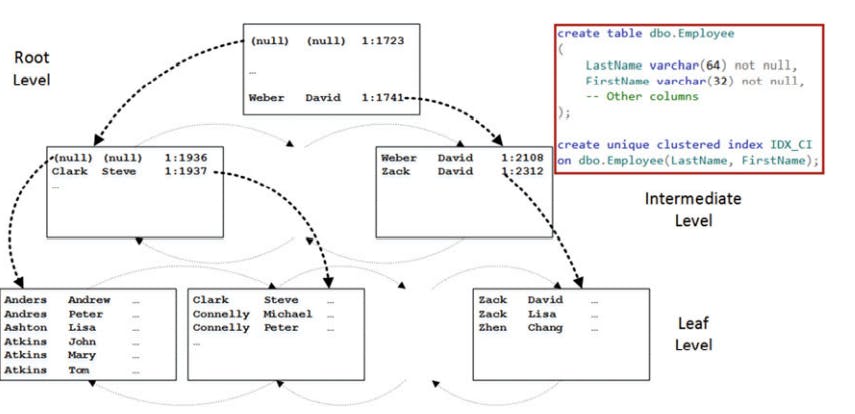
The SARGability of a composite index depends on the SARGablility of the predicates on the leftmost index columns.
the following figure shows the SARGable and non on a composite index.
