Pro Sql Sever Internals - Ch#1 - Data Storage Internals
Introduction to Sql Server



Database Files and Filegroups
Sql server database: is a collection of objects that allows you to store and manipulate data.
Database consists of one or more Transaction log file and 1 || *(1 or more) data file.
Transaction log : stores info about DB (database) transaction and all of data modification made in each session.
Any modification, sql server stores enough info in transaction log to undo or redo this action, to allow sql server to recover the DB to a transactionally consistent state in the event of an unexpected failure or crash.
Every DB has one primary data file which by default has an .mdf extension and has multi secondary data file by default .ndf extension.
All DB files are grouped into filegroups.
A filegroup is a logical unit that simplifies DB adminstration, it permits the logical sepration of DB objects and physical DB files.
create database [OrderEntryDb] on
primary
(name = N'OrderEntryDb', filename = N'm:\OEDb.mdf'),
filegroup [Entities]
(name = N'OrderEntry_Entities_F1', filename = N'n:\OEEntities_F1.ndf'),
filegroup [Orders]
(name = N'OrderEntry_Orders_F1', filename = N'o:\OEOrders_F1.ndf'),
(name = N'OrderEntry_Orders_F2', filename = N'p:\OEOrders_F2.ndf')
log on
(name = N'OrderEntryDb_log', filename = N'l:\OrderEntryDb_log.ldf')
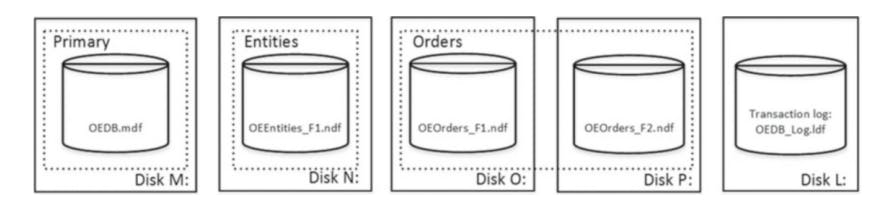
the above image shown, that there are 5 disks w/ 4 data file and one transaction log file. The dashed rectangles are the file groups.
Improve the I/O performance of system, may apply by put multi data file inside a filegroup to spread the load across different storage drivers take into consideration that DB is always available (CAP Theory)
Sql server works w/ transactional log sequentially and only one log file would be accessed at any given time.
create table dbo.Customers
(
/* Table Columns */
) on [Entities];
create table dbo.Articles
(
/* Table Columns */
) on [Entities];
create table dbo.Orders
(
/* Table Columns */
) on [Orders];
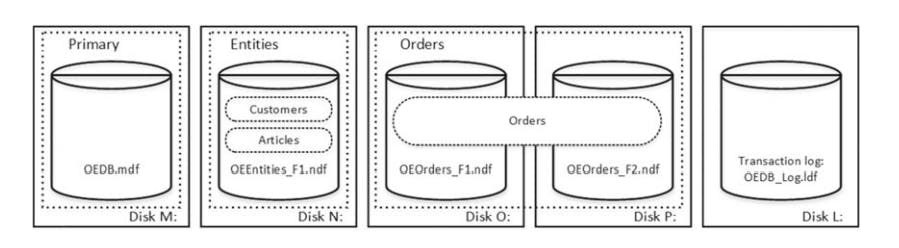
The sepration between logical objects in the filegroups and the physical DB files allows us to fine-tune the DB file layout to get the most out of the storage subsystem w/o worrying that it breaks the system.
specify initial file size and auto-growth parameters at the creation of DB or add new file to an existing DB, using Proportional fill algorithm when choosing to which data file it should write data, the more free space a file has, the more writes it handles.

setting the same initial size and auto growth paramters for all files in the filegroup is usually enough to keep the proportional fill algorithm work efficiently.
Every time sql Server grows the files, it fills the newly allocated space with zeros, this process blocks all sessions that are writing to the corresponding file or, in the case of transaction log growth, generating transaction log records.
Auto Shrink, when this option os enabled sql server shrinks the database files every 30 minutes, reducing their size and releasing the space to the operating system. This is very resource intensive and is rarely useful.
Data Storage in sql Server
There are 3 ways in which sql server stres and works w/ data in DB
- Classic row based storage, data stored in rows that combine the data from all columns together.
- Column store Indexes.
- Column based storage.
Data pages structure
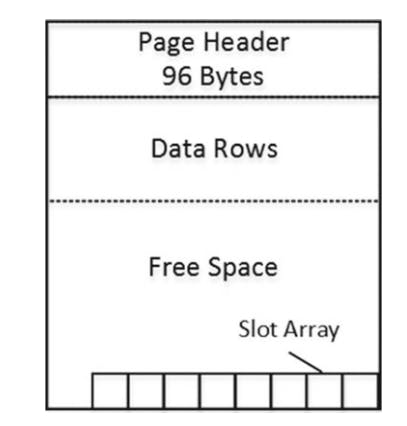
- page header, contains various pieces of info about page such as the obj to which page belongs, the #rows and amount of free space available on the page, links to previous and next pages if the page is in an index page chain.
- Data rows, area where actual data is stored.
Free space( slot array): block of 2 byte entries indicating the offset at which the corresponding data rows begin on the page. Slot array indicates the logical order of data rows on the page. If data on a page needs to be sorted in the order of index key, sql server doesn't physically sort the data row on the page, but rather it populates the slot array based on the index sort order.
- Slot 0 stores the offset for the data row w/ lowest key value on the page.
- Slot 1, the second lowest key value, and so forth
- Sql server offer a rich set of system data types that can be logically separated into 2 different groups
- Fixed Length, such as int, datetime, char, ... always use the same amount of storage space regardless of their value, even even it's null.
- Variable Length, such as varchar, varbinary, ... use as mush storage spae as is required to store data, plus 2 extra bytes. for example, an nvarcar(4000) clumn would be use only 12 bytes to store 5 character string and in most case 2 bytes to store a null value.
This Image shows the Data row Structre
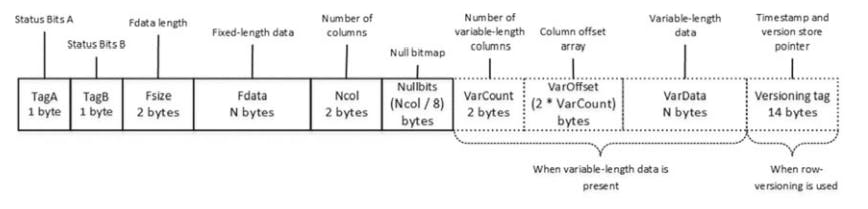
The first 2 bytes of row called Status Bits A and Status Bits B are bitmaps that contain info about the row such as row type, if row has been logically deleted (ghosted), and if the row has null value, variable length columns and a versioning tag.
The next 2 Bytes in row are used to store the length of fixed length portion of data. They are followed by the fixed length data itself.
After fixed length data portion, there is a null bitmap, which includes two different data elements.
- The first 2 byte element is #columns in the row.
- The second is a null bitmap array. This array uses one bit for each column of table, regardless of whether it's nullable or not.
A null bitmap is always present in data rows in heap tables or clustered index leaf row, even when the table doesn't have nullable columns. However, the null bitmap is not present in non leaf index rows nor in leaf level rows of non clustered indexes when there are no nullable columns in index.
Variable length data portion of row. it starts w/ a two byte number of variable length columns in row followed by a column offset array. sql server stores 2 bytes value for each variable length column in row even the value is null.
there is an optional 14-byte versioning tag at the end of row. This tag is used during operations that require row versioning such as an onnline index rebuild, optimistic isolation levels, triggers and few others.
create table dbo.DataRows
(
ID int not null,
Col1 varchar(255) null,
Col2 varchar(255) null,
Col3 varchar(255) null
);
insert into dbo.DataRows(ID, Col1, Col3) values (1,replicate('a',10),replicate('c',10));
insert into dbo.DataRows(ID, Col2) values (2,replicate('b',10));
// dbcc ind returns info about table page allocation
dbcc ind
(
'SQLServerInternals' /*Database Name*/
,'dbo.DataRows' /*Table Name*/
,-1 /*Display information for all pages of all indexes*/
);

- There are 2 pages that belongs to the table.
- The first one, with pageType =10 is a special type of page called an IAM allocation map. This page tracks the pages that belongs to a particular object.

The page with PageType=1 is the actual data page that contains the data rows. The PageFID and PagePID columns shows the actual file and file and page numbers for the page.
the data page with pageType=3 represents the data page that stores row overflow
-- Redirecting DBCC PAGE output to console
dbcc traceon(3604);
dbcc page
(
'SqlServerInternals' /*Database Name*/
,1 /*File ID*/
,214643 /*Page ID*/
,3 /*Output mode: 3 - display page header and row details */
);
DBCC PAGE output for first row
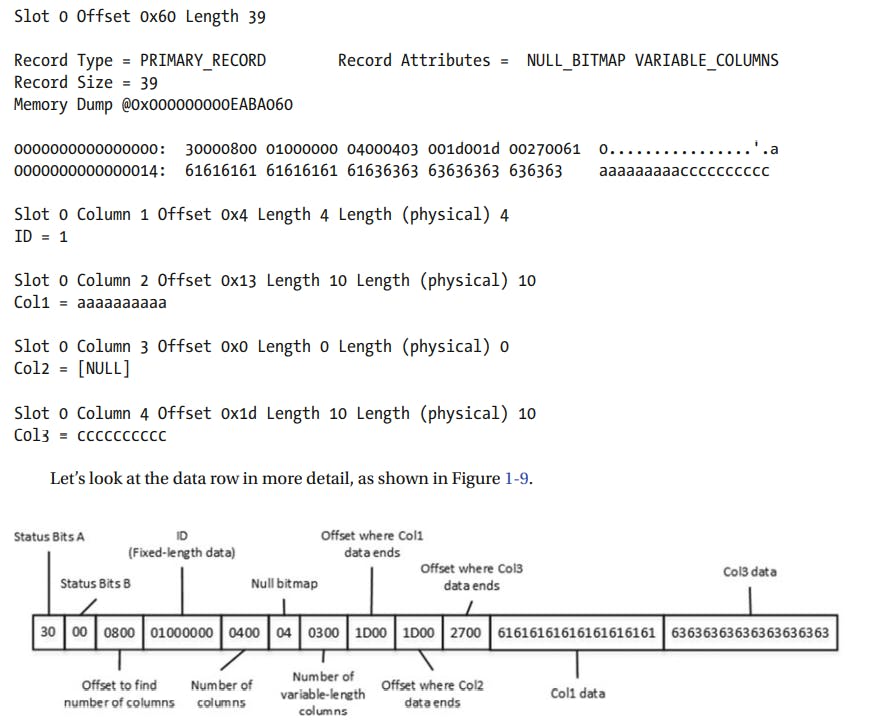
the row starts w/ 2 status bits followed by a 2 byte-value of 0800. this is the byte-swapped value of 0008, which is the offset for #columns attribute in the row. This offset tells sql server where the fixed length data part of row ends.
The next 4 bytes are used to store fixed length data, which ID column in our case.
- There is 2 byte value that shows that the data row has 4 columns, followed by a one-byte null bitmap. w/ just 4 columns, one byte in bitmap is enough. it stores the value of 04, which is 00000100 in the binary format. it indicates that the third column in row contains a null value.
- the next 2 bytes store #variable length columns in row, which is 3 (0300 in byte-swapped order). it's followed by an offset array, in which every 2 bytes store the offset where the variable length column data ends.
- Finally, there is the actual data from the variable length columns.
- The fixed length data and internal attributes must fit into the 8060 bytes available on the single page.
create table dbo.BadTable
(
Col1 char(4000),
Col2 char(4060)
)
/*
Msg 1701, Level 16, State 1, Line 1
Creating or altering table 'BadTable' failed because the minimum row size would be 8,067,
including 7 bytes of internal overhead. This exceeds the maximum allowable table row size of
8,060 bytes. */
Large Objects Storage.
There are two different ways to store the data, depending on the data type and length.
Row-Overflow Storage
Sql server stores variable length column data that doesn't exceed 8000 bytes on special pages called row-overflow pages
create table dbo.RowOverflow
(
ID int not null,
Col1 varchar(8000) null,
Col2 varchar(8000) null
);
insert into dbo.RowOverflow(ID, Col1, Col2) values
(1,replicate('a',8000),replicate('b',8000));

- the data page with pageType=3 represents the data page that stores row overflow.

LOB Storage
For text, nText or image columns, sql server stores the data off row by default. it uses another kind of pages called LOB data pages
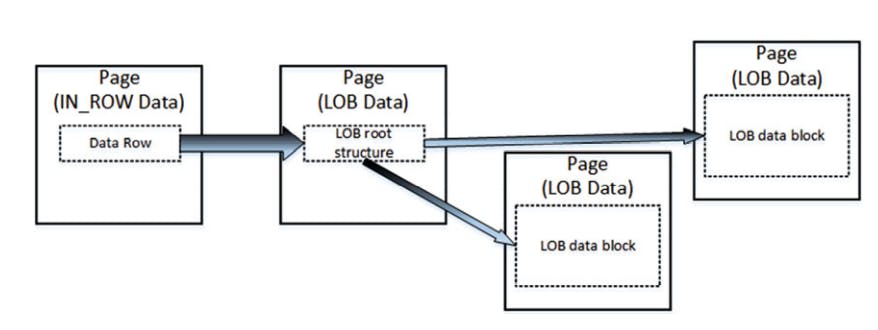
As with row overflow data, ther is a pointer to another piece of info called LOB root structure which contains a set of pointers to other data pages and rows. when LOB data is less than 32 data. Otherwise, the LOB tree starts to includes additional intermediate levels of pointers, similar to the index B_Tree.
create table dbo.TextData
(
ID int not null,
Col1 text null
);
insert into dbo.TextData(ID, Col1) values (1, replicate(convert(varchar(max),'a'),16000));

The table stores less metadata info in the pointer and uses 16 bytes rather than the 24 bytes required by the 2 row overflow pointer.

SELECT * and I/O
select * operator is not a good idea :-
- it increase network traffic by transmitting columns that the client app doesn't need.
- it makes query performance tuning more complicated and it introduces side effects when table schema changes.
create table dbo.Employees
(
EmployeeId int not null,
Name varchar(128) not null,
Picture varbinary(max) null
);
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows
,N5(C) as (select 0 from N4 as T1 cross join N2 as T2) -- 1,024 rows
,IDs(ID) as (select row_number() over (order by (select null)) from N5)
insert into dbo.Employees(EmployeeId, Name, Picture)
select
ID, 'Employee ' + convert(varchar(5),ID),
convert(varbinary(max),replicate(convert(varchar(max),'a'),120000))
from Ids;
select * from dbo.Employees;
select EmployeeId, Name from dbo.Employees;

As u see, the first select, which reads the LOB data and trasmits it to client, is a few orders of magnitude slower than the second select.

Extents and Allocation Map Pages
sql serve logically groups 8 pages into 8KB units called extents. There are 2 types of extents available :-
- mixed extents: store data belongs to different objects.
- uniform extents: store data for same object.
By default, when a new object is created, sql server stores the first 8 object pages in mixed extents. After that, all subsequent space allocation for that object is done with uniform extents.
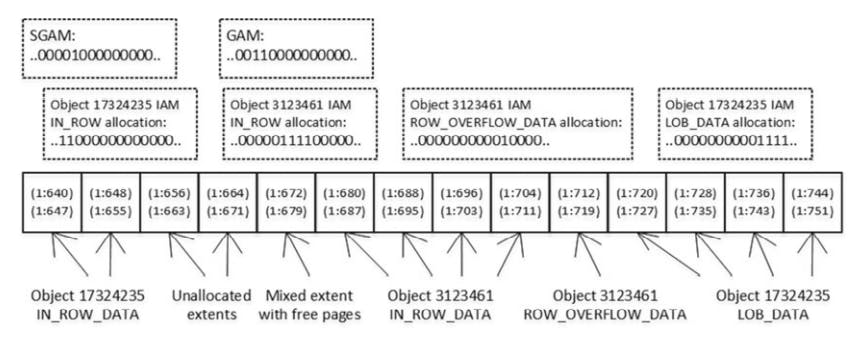
Sql server uses a Special kind of pages called allocation maps to track extent and pages usage in a file.
There are serval different types of allocation map pages in sql server:-
- Global allocation map(GAM) pages track if extents have been allocated by any objects. The data os represented as bitmap, where each bit indicates the allocation status of an extent.
- Zero bits=> the corresponding extents are in use.
- one bits=> the corresponding extents are free.
every GAM page cover about 64000 extents or almost 4 GB of data. This means that every database file has one GAM page for about 4 GB of file size.
- Shared global allocation map(SGAM) pages track info about mixed extents.
- Zero bits=> the corresponding extent is a mixed and has at least one free page available.
- one bits=> the corresponding extent unifor extent || full mixed extent.

- Page free space(PFS): track a few different things, we call PFS as a byte mask, where every byte stores info about a specific page
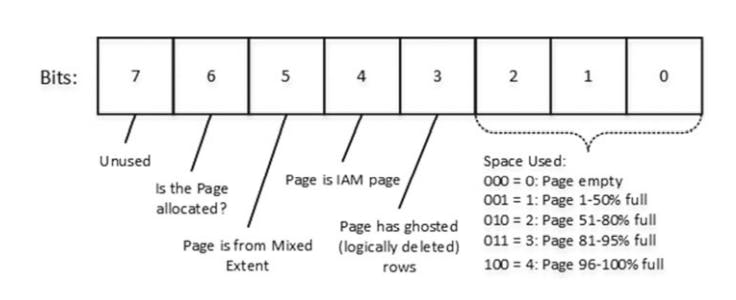
- The first 3 bits in the byte indicate the % used space on page.
- when delete a data row from table, sql does not remove it from data page, but rather marks the row as deleted. Bit 3 indicates whether the page has logically deleted (ghosted) rows.
- Bit 4 indicates if the page is an IAM page.
- Bit 5 indicates whether or not page is the mixed extent.
- Bit 6 indicates if page is allocated.
Every PFS page track 8088 pages or about 64 MB of data space. It's always the second page(page 1) in the file and every 8088 pages thereafter.
Differential changed map (DCM): (page 6), these pages keep track of extents that have been modified since the last full database bakup. sql server use DCM pages when it performs DIFFERENTIAL backup.
bulk changed map (BCM): (page 7), it indicates which extents have been modified in minimally logged operations since the last transaction log bakup.
* BCM pages are used only w/ a BULK-LOGGED database recovery model.
When SQL Server needs to allocate a new uniform extent, it can use any extent where a bit in the GAM page has the value of one. When SQL Server needs to find a page in a mixed extent, it searches both allocation maps looking for the extent with a bit value of one in an SGAM page and the corresponding zero bit in a GAM page. If there are no such extents available, SQL Server allocates the new free extent based on the GAM page, and it sets the corresponding bit to one in the SGAM page.
Sql server tracks the pages and extents used by the different types of pages ( IN_ROWDATA , ROW OVERFLOW , and LOB pages) that belong to the object with another set of the allocation map pages, called the index allocation map (IAM) .
Every table/index has its own set of IAM pages, which represents the bitmap, where each bit indicates if a corresponding extent stores the data that belongs to a particular allocation unit for a particular object.
Data Modifications
Sql server doesn't read || modify data row directly on the disk. Every time you access data, sql reads it into memory.
There is a memory cash, called a buffer pool, that chaches some of data pages.
Initial stage of database before an update operation*.
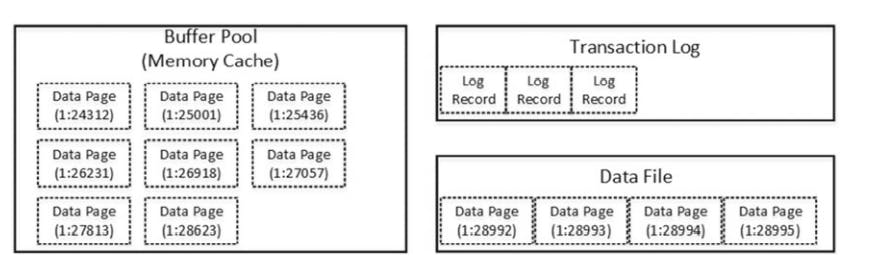
let's assume that you wanna update the data row from the page (1:28992). This page not in buffer pool, sql needs to read the data page from disk.
- when the page in memory, sql update the data row. This process includes 2 different steps:-
- First: sql generates a new transaction log record and synchronously writes ot to the transaction log file.
- Second: it modifies the data row and marks the page as modified(dirty)
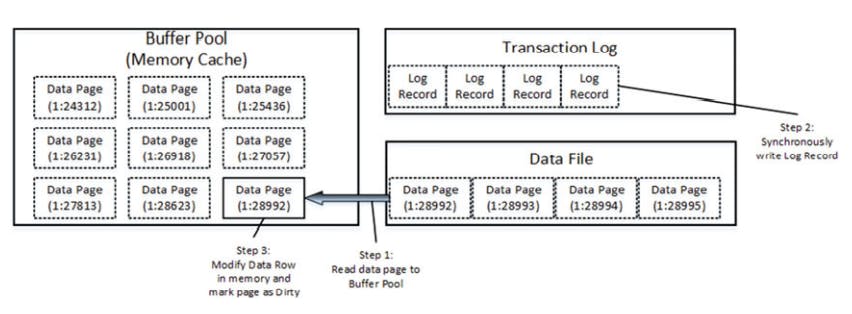
Even though the new version pf data row is not saved in data file, the transaction log record contains enough info. to reconstruct (redo) the change if needed.
finally, at some point sql async. save the dirty data pages intp the data file and a special log record into the transaction log. This process is called a check point
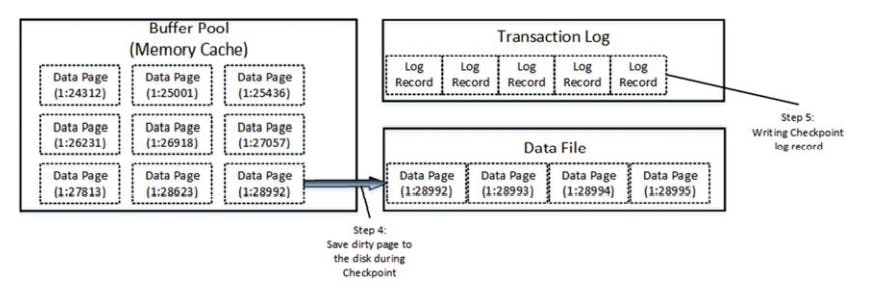
The Insert process in similar a manner. sql reads data page where the new data row needs to be inserted into the buffer pool || it allocates a new extent/page if needed.
After that, sql sync. save the transaction log record, insert into the page, and async. save the data page to disk.
The deletions Process is the same. As mentioned before, when delete a row, sql doesn't physically remove the row from the page. rather, it flags deleted row as ghosted(deleted) in the status bits. this speeds up deletion and allow sql to undo it quickly if necessary.
The deletion process also sets a flag in the PFS page indication that there is a ghosted row on the page.
sql removes a ghosted row in the background through a task called ghost cleanup
there is another sql process called lazy writer that can save dirty pages on disk. As the opposite to check point, which save dirty data pages by keeping the in the buffer pool, lazy writer processes the least recently used data pages( sql tracks buffer pool pages usage internally) releasing them from memory. It releases both dirty and clean pages, saving dirty data pages on dist during the process.
lazy writer runs in case of memory pressure or when sql needs to bring more data pages to the buffer pool.
Keep in mind
- when sql processes DML queries, it never works with data w/o first loading the data pages into buffer pool.
- when modifying the data, sql sync writes log records to the transaction log. the modified data pages are saved to data files async, in background.
Much Ado about Data Row Size
As known, sql is a very I/O intensive app. sql can generate an enormous amount of I/O activity especially when dealing w/ large number of concurrent users.
There are many factors that affet the performance of queries, and the number of I/O operations involved is at the top of list, like:-
- the more I/O operations a query needs to perform, the more data pages it needs to read, and the slower it gets.
- the size of data row affects how many rows will fill in data page. large data require more pages to store the data and as a result, increase the number of I/O operations during scans.Moreover, Objects will use more memory in the buffer pool.
// dbo.LargeRows ,
//uses a char(2000) fixed-length data type to store the data.
create table dbo.LargeRows
(
ID int not null,
Col char(2000) null
);
// dbo.SmallRows , uses a varchar(2000)
// variable-length data type
create table dbo.SmallRows
(
ID int not null,
Col varchar(2000) null
);
//populate both of the tables with the same data.
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows
,N5(C) as (select 0 from N4 as T1 cross join N4 as T2) – 65,536 rows
,IDs(ID) as (select row_number() over (order by (select null)) from N5)
insert into dbo.LargeRows(ID, Col)
select ID, 'Placeholder' from Ids;
insert into dbo.SmallRows(ID, Col)
select ID, 'Placeholder' from dbo.LargeRows;
to compare the number of I/O operations and execution times. we use select statement.
select count(*) from dbo.LargeRows;
select count(*) from dbo.SmallRows;

Sql needs to perform about 70 times more reads while scanning dbo.LargeRows data, which leads to the longer execution time.
By reducing the size of data row, this improve performance of the system.
one way to do this by using the smallest data type that covers the domain values when creating tables. for example:
Use bit instead of tinyint , smallint, or int to store Boolean values. The bit data type uses one byte of storage space per eight columns.
Use the appropriate date/time data type based on the precision you need. For example, an order-entry system can use smalldatetime (four bytes of storage space) or datetime2(0) (six bytes of storage space) rather than datetime (eight bytes of storage space) to store information on when an order was placed into the system when one-minute or one-second precision is enough.
Use decimal or real rather than float whenever possible. Similarly, use money or smallmoney data types rather than float to store monetary values.
Do not use large fixed-length char/binary data types unless the data is always populated and static in size.
Table that collects location information

this comparison, affects buffer pool memory usage, backup file size, network bandwidth, ... .
Table Alteration
What happens when altering table, there are different ways that sql can proceed, as follows: 1- Alteration requires changing the meta data only,like dropping a column, changing a not nullable column to a nullable one, or adding a nullable column to table.
2- Alteration requires changing the metadata only, but sql server needs to scan table data to make sure it conforms to the new definition, like changing a nullable column to be not nullable. sql needs to scan all data rows in the table to make sure that there are no null values stored on a particular column before changing the table metadata.
3- Alteration requires changing every data row in addition to the metadata, like an operation is changing a column data type in a way that requires either a different storage format or a type conversion. For example, move data from the fixed to variable length section of the row. Another example is when changing char data type to int, but sql server must physically update every data row in the table converting the data.
It's worth nothing that table-locking behavior during alteration is version and edition specific. For example, the Enterprise Edition of Sql 2012 allows adding a new NOT NULL column, instantly storing the info. at the metadata level w/o changing every row in table.

If you think Alteration for table is good, pleas wait for a second ...
Table alteration never decreases the size of data row. when dropping a column from a table, sql doesn't reclaim the space that the column used.
When changing data type to decrease the data length, like from int to smallint , sql continues to use same amount of storage space as before while checking that row values conform to the new data-type values.
When changing data type to increase the data length, like from int to bigint, sql adds new column under the hood and copies the original data to the new column in all data rows.
create table dbo.AlterDemo
(
ID int not null,
Col1 int null,
Col2 bigint null,
Col3 char(10) null,
Col4 tinyint null
);
select
c.column_id, c.Name, ipc.leaf_offset as [Offset in Row]
,ipc.max_inrow_length as [Max Length], ipc.system_type_id as [Column Type]
from
sys.system_internals_partition_columns ipc join sys.partitions p on
ipc.partition_id = p.partition_id
join sys.columns c on
c.column_id = ipc.partition_column_id and
c.object_id = p.object_id
where p.object_id = object_id(N'dbo.AlterDemo')
order by c.column_id;
The following picture shows the column offsets before table alteration
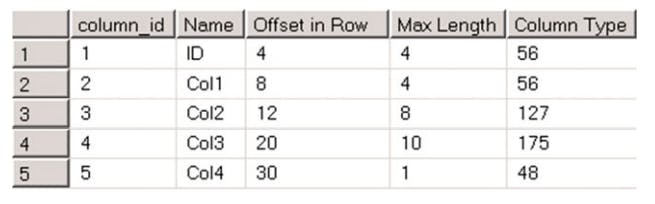
alter table dbo.AlterDemo drop column Col1;
alter table dbo.AlterDemo alter column Col2 tinyint;
alter table dbo.AlterDemo alter column Col3 char(1);
alter table dbo.AlterDemo alter column Col4 int;
the next image shows the column offsets after change
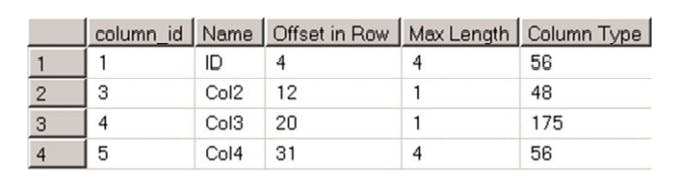
Even though we dropped the col1 column, the offsets of the col2 and col3 columns have not been changes. Moreover, both the col2 and col3 columns require just one type to store the data, although it does not affect the offsets of either.
Finally, col4 column offset has been changed. This column data length has been increased, and sql created the new column to accommodate the new data type values.
The only way to reclaim the space is by rebuilding a heap table or clustered index
ALTER TABLE dbo.AlterDemo REBUILD
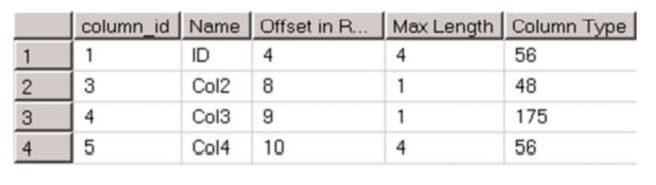
As you see, the table rebuild reclaims the unused space from the rows. table alteration requires sql server to obtain a schema modification ( SCH-M) lock on the table. It make table inaccessible by another session for the duration of the alteration